
UNCROSS algorithm
See also
Cross-talk
uncross command
UNCROSS paper
Manual annotation of cross-talk
Cross-talk can be identified by examining an OTU table . If the lowest-abundance samples in a given OTU have much lower counts than the high-abundance samples, they are probably due to cross-talk and should be zero.
You can clearly see cross-talk in this GAIIx example and this MiSeq example .
See the UNCROSS paper for a more formal and complete description of the algorithm.
In a mock sample, a high-abundance unexpected OTU, i.e. an OTU which does not match a species in the designed community, is probably a contaminant.
A low-abundance unexpected mock count is probably cross-talk if it is also present in another sample. An alternative explanation is a low-abundance contaminant in the mock sample which is a valid OTU in the environmental samples by coincidence; this is a much less likely explanation. Another possible explanation is contamination which affects multiple samples, e.g. flow-cell residue from previous runs; this is also considered to be less likely than cross-talk.
Under these assumptions, mock samples enable a more sensitive test for the presence of cross-talk. For example, if an unexpected mock OTU has two reads and some other sample has ten reads then the most likely explanation is cross-talk. The anomalously large cross-talk rate of 2/12 = 17% of the reads can be explained by fluctuations due to sampling effects when there are small total numbers of reads, which can result in high outlier values for some OTUs. In environmental samples, OTUs cannot be considered as expected or unexpected so abundances of two and ten in an OTU with twelve total reads is not a reliable indicator of cross-talk.
Automated annotation of cross-talk
The UNCROSS algorithm uses simple heuristics to automate the manual procedure described above for annotating cross-talk. UNCROSS-Ref predicts cross-talk in mock samples where OTUs are annotated as matching (or not matching) the designed mock community. UNCROSS-Denovo predicts cross-talk in all samples considering read counts alone. These approaches are complementary. UNCROSS-Ref can identify unexpected OTUs by comparison with the database and is thus more sensitive to cross-talk in OTUs with low overall abundance, but cannot detect or correct cross-talk in environmental samples. UNCROSS-Denovo is less sensitive to cross-talk in OTUs with low overall read counts, but can detect cross-talk in environmental samples and can thus be used to detect and correct cross-talk in practice.
UNCROSS is not a robust solution for cross-talk
The mechanism(s) causing cross-talk are not well understood. Many different indexing schemes are used. Cross-talk rates in your data may be quite different from the datasets on which UNCROSS was designed and tested, in which case the accuracy of UNCROSS on your data may be lower. Also, cross-talk may be hard or impossible to detect when the number of multiplexed samples is large, say around 100 or more. It is much better to use multiplexing strategies that are designed to reduce cross-talk. UNCROSS is best understood as a simplisitc hack that is the best we can do with exisitng data.
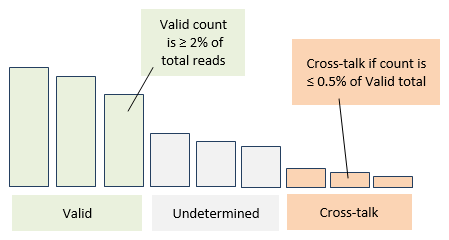
Schematic illustration of the UNCROSS-Denovo algorithm. The OTU table entries for a given OTU are shown sorted by decreasing count (number of reads). If a count is at least 2% then it is classified as valid. If a count is <= 0.5% of the total over valid counts, it is predicted to be due to cross-talk. Intermediate values are classified as undetermined.
