See also
Taxonomy benchmark home
Validating taxonomy classifiers
Training taxonomy classifiers
UTAX algorithm
"Splitting" is a method used for training and validating taxonomy classifiers. The example below illustrates splitting at family level.
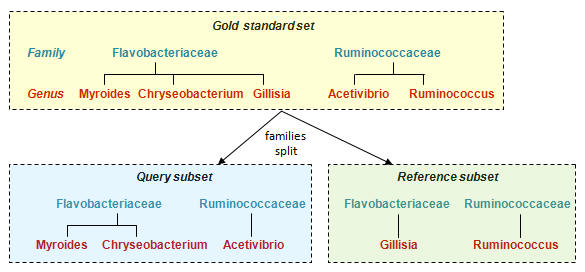
Split at family level
Divide genera for each family into two random subsets, one for the Query subset
and one for the Reference subset. (Discard families with only one genus). A
classifier algorithm is trained on the Reference subset.
With a family level split, a family is always present in both Query and Reference, genus is never present in both.
The taxonomy classifier would ideally predict family level correctly for all query sequences because at least one training example of the family is known to be present in the Reference. If the wrong family is predicted, this is a misclassification error, if no family is predicted this is a underclassification error. See taxonomy classification errors for further discussion.
The genus of a Query sequence is never present in the
Reference, so if a genus is predicted this is an
overclassification error.