See also
Taxonomy benchmark home
Taxonomy overclassification error
results
Taxonomy overclassification and
underclassification errors
Taxonomy prediction errors
UTAX algorithm
Validating taxonomy prediction methods
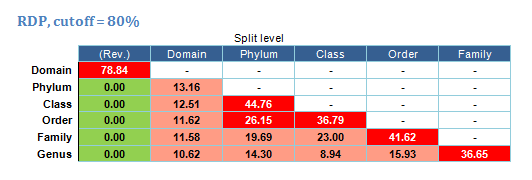
Below is an example table showing the overclassification error rates for the RDP classifier at 80% bootstrap cutoff on the V3-V5 region.
Columns are split levels, rows are levels predicted by the classifier. The split level is the lowest common level (LCL, see overclassification errors for explanation). So, for example, if the split level is phylum, a classifier should ideally predict the phylum but nothing lower -- predictions for class, order, family or genus would be overclassification errors.
An entry is the percentage of query sequences that are overclassified at the given prediction level. For example, in the table below the genus overclassification rate is 14.30% with a phylum split. This means that genus was incorrectly predicted for 14.30% of the query sequences when in fact the closest taxon in the reference (training) set was phylum. Colors are used to indicate low or high error rates, for example dark green shows error rates <1% and dark red is >25%.
The (Rev.) column shows results where the query set is constructed by reversing (not reverse-complementing) all the sequences in the gold standard set. In this case, all predictions are false positives that can be considered to be overclassification errors.